
Welcome to the blog posts of the SAP CX Services Marketing Practice.
We are happy to share with you our experience around Marketing Business, Technology and Analytics.
You want to see more blogs from us? Click here.

Background
With SAP Marketing Cloud, one can create recommendation models that provide consumers with relevant recommendations across multiple sales channels. The logic on how recommendation models return recommendations can be built using a combination of multiple (out-of-the-box or custom) algorithms.
The recommendations can be later used directly in marketing campaigns or externally consumed through APIs, which e.g. return product recommendations for the items the consumer is currently looking at based on products which are often bought together. A standard integration with SAP Commerce exists – product recommendations from SAP Marketing Cloud can be displayed on the web shop.
The topic around product recommendations has multiple aspects. This blog post focuses on how one can implement custom algorithms for product recommendations using the extensibility concept of SAP Marketing Cloud. Aspects such as the integration of product recommendations into other solutions or recommended practices on productive architectures are not covered in this post.
There are a couple of scenarios which can be covered by out-of-the-box algorithms in SAP Marketing Cloud. Two examples are:
-
- Scenario A) Most viewed products based on interaction data of the last Y days
-
- Scenario B) Cross-sell based on interaction purchase history of the last X days
Scenario A) is a straight forward scenario, returning the top viewed products based on SHOP_ITEM_VIEW interactions in SAP Marketing Cloud. The underlying algorithm is a query algorithm. Scenario B) can be based on an association algorithm such as Apriori Lite, returning products that have often been bought together in a given time period. In this cross-sell scenario, it might make sense to also include a post-processing algorithm to remove items which are already in the customer’s cart in a second step.
As shown above, various out-of-the-box algorithms can be combined into simple or complex scenarios. However, if a given scenario can’t be covered by the out-of-the-box algorithms for product recommendations, custom algorithms are required.
User story and business question
Two examples for scenarios which can be implemented by a custom algorithm are:
-
- Scenario C) Similar products based on product master data
-
- Scenario D) Up-sell more expensive products from same product category
Similar products based on product master data
Scenario C) serves as a typical use case for product similarity using heuristics. Depending on the industry and the availability of product master data, the definition of product similarity can of course vary. In our example we take an example from the film industry based on movie data.
The data set for our scenario is taken from a public source, The Movie Database API.

Lets assume we are a company specialized in streaming and video-on-demand services. Apart from classic recommendations such as “what other users watched”, we want to build an easy movie recommendation scenario for “similar movies” (e.g. based on genre, running time, release year).
A subset of the TMDb dataset looks like this (any resemblance to my personal preferences is purely coincidental):
| Movie | Genres | Running time | Release year | […] |
| The Shawshank Redemption | Drama, Crime | 142 min | 1994 | […] |
| Interstellar | Adventure, Drama, Science Fiction | 169 min | 2014 | […] |
| The Martian | Adventure, Drama, Science Fiction | 141 min | 2015 | […] |
| […] | […] | […] | […] | […] |
Each movie in this dataset has been converted into a product, having extension attributes such as running time and release year. The genres have been converted into product categories.
Our custom algorithm for product similarity now has to take these three attributes into account.
Up-sell more expensive products from same product category
Scenario D) is a typical use case being valid in many industries, for example the consumer electronics line of business. The idea here is that a standard algorithm such as the cross-sell scenario B) already returns products which are often bought together (e.g. a smart phone case together with the smart phone).
However, we want to re-rank the results by influencing the recommended product list. In a nutshell, we want to show the more expensive products from the same product category first (e.g. first showing the 30$ smart phone case although the 10$ smart phone case is often bought together with smart phone A).
Implementation
In the following, the implementation steps are outlined for both scenarios. The first step is the HANA view modelling, followed by the import of the HANA view into SAP Marketing Cloud and the configuration of the algorithm. In the end we can test our custom algorithm by creating a recommendation model using our algorithm.
Following the Extensibility Guide for SAP Marketing Cloud, we create a “Recommendation Runtime” view which has to contain a join with the PRECO_CX_TASK table for both scenarios. Among others, this table contains the maximum number of recommended items set by the user. The result set of the view has to contain the following:
-
- TASK_ID (integer)
-
- RESULT_ITEM (varbinary 16)
-
- RESULT_ITEM_TYPE (nvarchar 2)
-
- SCORE (double)
Similar products based on product master data
After our custom extension fields for our products (movie meta data) are created and the movie data is imported into SAP Marketing, we can build our custom HANA view for product similarity.
The most important nodes of our HANA view are the following (a screenshot of the HANA view is shown below):
-
- This mandatory table needs a filter on ALGO_ID using the custom algorithm name we want to use (here: Z_RECO_MOVIE_1)
-
- In this join, we get the product master data for our leading product
-
- Using this join, we get the product category for our leading product
-
- Here we find all products from the same product category
-
- This is the most important node of our view. We use two calculated columns, one for the product keys which follow our custom similarity condition (similar release year, similar runtime) in addition to the product category match. The second calculated column is a similarity score (the lower the more similar both products are).Our similarity condition is based on the heuristic that
-
- the genres / product categories have to match [using nodes 3 and 4] and
-
- that the absolute difference between the release years is below 8 years and
-
- that the absolute difference between the run times is below 30 minutes. The resulting calculated column in node 5 is shown below:

- that the absolute difference between the run times is below 30 minutes. The resulting calculated column in node 5 is shown below:
-
- This is the most important node of our view. We use two calculated columns, one for the product keys which follow our custom similarity condition (similar release year, similar runtime) in addition to the product category match. The second calculated column is a similarity score (the lower the more similar both products are).Our similarity condition is based on the heuristic that
-
- Here we calculate the minimum score across all similar items
-
- In this join, we calibrate all scores using the minimum score
-
- Using the rank node, we rank the different results
-
- Last but not least we need to take care that our algorithm only returns the maximum number of recommended items

Now we need to upload our HANA view into SAP Marketing Cloud using the “Add Custom View” app and the view usage type of “Recommendation Runtime”.
The last configuration step is in the “Manage your solution” app. In the “Configure your solution” section, search for Recommendation-configureAlgorithm. Here you find all standard algorithms. We need to create a new one. It’s crucial to use the same algorithm ID chosen in node 1 of the HANA model. In this example, this algorithm should be part of the “recommend” step type (in contrast to the “remove items already in the cart”, which is part of the “filter” algorithms).
Select the SAP HANA view we have uploaded in the previous step and set the algorithm to optimized. Optimized algorithms enable recommendations to be cached and used for similar consumers. As a result, future requests for the same recommendations can be provided much faster with less resource consumption. (taken from the product documentation)

Now we can start using the algorithm in a recommendation model. Using the preview functionality, we can try it out using the data in the system and confirm that it works.

Up-sell more expensive products from same product category
Our second scenario has several similarities with the previous scenario. One aspect is that also products from the same product category shall be taken into account. That’s the reason why the resulting HANA view looks very similar to the one above.
The main difference is in node 5 (comparing to the HANA view from scenario C). In this example, in order to satisfy the up-sell requirement, we take the more expensive item by comparing the AMOUNT1 field in an calculated column as shown below.
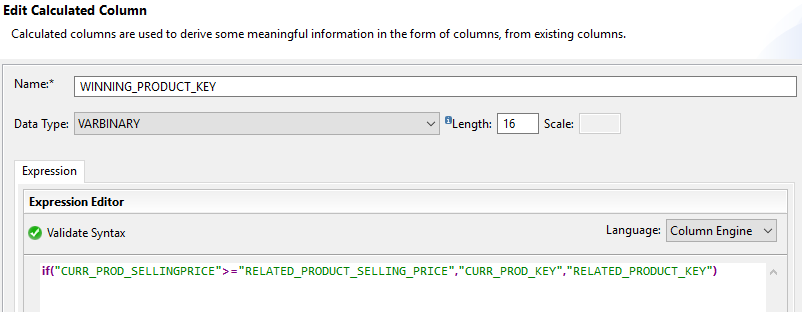
The remaining steps are almost identical. The HANA view being the basis for this scenario can also be downloaded via SAP note 2543147 – Example of an upselling recommendation using field AMOUNT1.
Summary
In this blog post, the implementation of custom algorithms for product recommendations using the extensibility concept of SAP Marketing Cloud has been presented by implementing two custom scenarios:
-
- Similar products based on product master data
-
- Up-sell more expensive products from same product category
All necessary steps from creating the HANA view to previewing the result of our algorithm have been presented.
Acknowledgements
The dataset for scenario C) was generated from The Movie Database API. This blog post uses the TMDb API but is not endorsed or certified by TMDb. Their API also provides access to data on many additional movies, actors and actresses, crew members, and TV shows. You can try it for yourself here.
You want to see more articles from SAP Services? Click on the banner below.
Your SAP CX Services – Marketing Practice team.
